
- Dołączył
- 26 Maj 2015
- Posty
- 19203
- Reakcje/Polubienia
- 55884
Pete napisał robota, który przeszedł się po publicznych profilach Facebookowych podobnie jak roboty wyszukiwarek internetowych, np. Google. Co ważne, jego robot respektował Facebookowy plik robots.txt. Zebrane dane Pete zanonimizował i chciał udostępnić wszystkim zainteresowanym do analizy. Niestety, nie dał rady, bo został pozwany.
Na dzień dzisiejszy, plik
Pete przez 6 miesięcy, przestrzegając powyższych zapisów, crawlował *publicznie dostępne* profile z Facebooka (zebrał ich 210 milionów). Początkowo chciał zrobić internetową książkę telefoniczną, bazując na zebranych danych, ale zauważył że z publicznych profili Facebooka da się wyciągnąć więcej: listy przyjaciół danej osoby oraz nazwy stron, których jest się fanem.
Pete pokusił się zatem o głębszą analizę i wystawił swoje dane na stronie
“Cycki sprzedadzą wszystko”
Pete uciekł się więc do haniebnego, ale skutecznego zabiegu. Zwizualizował zebrane przez siebie dane, i zamiast poważnego języka statystyki, opisał je
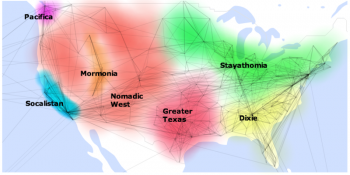
Facebook i zależności pomiędzy jego użytkownikami
Wśród nich jedank był prawnik Facebooka, wraz z szefem bezpieczeństwa, którego Pete znał, bo zgłosił mu uprzednio kilka dziur w Facebooku. Prawnik powiedział Pete’owi, że chcą go pozwać, ale ze względu na dobre relacje, które utrzymywał z szefem bezpieczeństwa, postanowili mu dać szansę :>
Facebooka podejście do robots.txt
Facebook uważa, że plik robots.txt nie zezwala nikomu pobierać danych z serwisu (podkreślam jeszcze raz publicznie dostępnych danych) bez uprzedniej pisemnej zgody. Pete uważa, że nie tak działał internet przez ostatnie 16 lat, ale jego prawnik ma inne zdanie — ponoć nikt nie przetestował jeszcze “robots.txt” w sądzie :>
Crawling Nasza-Klasa.pl
Doskonale rozumiem zapędy Pete’a, bo z publicznie dostępnych danch serwisów społecznościowych można wyciągnąć od groma pożytecznych informacji (znawcom teorii grafów podpowiadam:
Podobny do Pete’a eksperyment przeprowadziłem kilka lat temu na naszym rodzimym serwisie społecznościowym. Nasza-Klasa miała jeszcze wtedy kilka błędów w logice ustawień prywatności, a więc i dane, które można było wyciągnąć były ciekawsze.
Cytując fragment
Na dzień dzisiejszy, plik
Zaloguj
lub
Zarejestruj się
aby zobaczyć!
Facebooka wygląda tak:
Kod:
Zaloguj
lub
Zarejestruj się aby zobaczyć!
Pete przez 6 miesięcy, przestrzegając powyższych zapisów, crawlował *publicznie dostępne* profile z Facebooka (zebrał ich 210 milionów). Początkowo chciał zrobić internetową książkę telefoniczną, bazując na zebranych danych, ale zauważył że z publicznych profili Facebooka da się wyciągnąć więcej: listy przyjaciół danej osoby oraz nazwy stron, których jest się fanem.
Pete pokusił się zatem o głębszą analizę i wystawił swoje dane na stronie
Zaloguj
lub
Zarejestruj się
aby zobaczyć!
…ale nikt się tym nie zainteresował (ok. 5 internautów dziennie odwiedzało tę stronę).“Cycki sprzedadzą wszystko”
Pete uciekł się więc do haniebnego, ale skutecznego zabiegu. Zwizualizował zebrane przez siebie dane, i zamiast poważnego języka statystyki, opisał je
Zaloguj
lub
Zarejestruj się
aby zobaczyć!
. To trafiło do ogółu i zostało podlinkowane z kilkudziesięciu stron napędzając mu internautów :>
Facebook i zależności pomiędzy jego użytkownikami
Wśród nich jedank był prawnik Facebooka, wraz z szefem bezpieczeństwa, którego Pete znał, bo zgłosił mu uprzednio kilka dziur w Facebooku. Prawnik powiedział Pete’owi, że chcą go pozwać, ale ze względu na dobre relacje, które utrzymywał z szefem bezpieczeństwa, postanowili mu dać szansę :>
Facebooka podejście do robots.txt
Facebook uważa, że plik robots.txt nie zezwala nikomu pobierać danych z serwisu (podkreślam jeszcze raz publicznie dostępnych danych) bez uprzedniej pisemnej zgody. Pete uważa, że nie tak działał internet przez ostatnie 16 lat, ale jego prawnik ma inne zdanie — ponoć nikt nie przetestował jeszcze “robots.txt” w sądzie :>
Crawling Nasza-Klasa.pl
Doskonale rozumiem zapędy Pete’a, bo z publicznie dostępnych danch serwisów społecznościowych można wyciągnąć od groma pożytecznych informacji (znawcom teorii grafów podpowiadam:
Zaloguj
lub
Zarejestruj się
aby zobaczyć!
).Podobny do Pete’a eksperyment przeprowadziłem kilka lat temu na naszym rodzimym serwisie społecznościowym. Nasza-Klasa miała jeszcze wtedy kilka błędów w logice ustawień prywatności, a więc i dane, które można było wyciągnąć były ciekawsze.
Cytując fragment
Zaloguj
lub
Zarejestruj się
aby zobaczyć!
sprzed kilku lat:źródło:Do czego mogą posłużyć dane masowo zebrane z Naszej Klasy?
Mnie do głowy przyszła internetowa książka numerów, zawierająca imię, nazwisko, miasto, wiek, telefon (komórkowy), numer GG, Skype. Dodatkowe informacje na temat osoby z książki można dociągnąć z baz Skype/GG.
Kolejny pomysł, to analiza statystyczna: jaki profil w danym mieście cieszył się największą popularnością? Ile osób z danego miasta jest na Naszej Klasie? Jak wygląda wektor migracji młodych osób (skąd, dokąd)? Ile Polaków jest (było) za granicą? Jakie imię jest najpopularniejsze? Ile osób o danym nazwisku jest w danym mieście?
Na podstawie zebranych danych można też (…) namierzyć dłużników lub zbudować profil zainteresowań danej osoby. Skoro ktoś kończył klasę o profilu biol-chem i studiował medycynę, na pewno będzie zainteresowany informacją o leku X…
Zaloguj
lub
Zarejestruj się
aby zobaczyć!