
- Dołączył
- 26 Maj 2015
- Posty
- 19210
- Reakcje/Polubienia
- 55916
źródło:DocFetcher jest programem open source, który został stworzony, aby pomóc nam w wyszukiwaniu plików na naszym komputerze, pozwalając zarazem na podejrzenie ich zawartości. Oczywiście do wyszukiwania można użyć narzędzia systemowego, ale będzie to trwało o wiele dłużej.
Indeksowanie i wyszukiwanie obiektów w programie oparte są na Apache Lucene, powszechnie stosowanej wyszukiwarki open source.
Jedną z wielu zalet aplikacji jest to, że jest dostępny w wersji przenośnej, która pozwala na stworzenie przenośnego repozytorium dokumentów w pełni indeksowanego. Można go nosić przy sobie na dysku USB, nagrać go na płytę CD-ROM dla celów archiwalnych, umieścić w zaszyfrowanym woluminie, synchronizować je między wieloma komputerami za pośrednictwem usługi chmury (np. Dropbox).
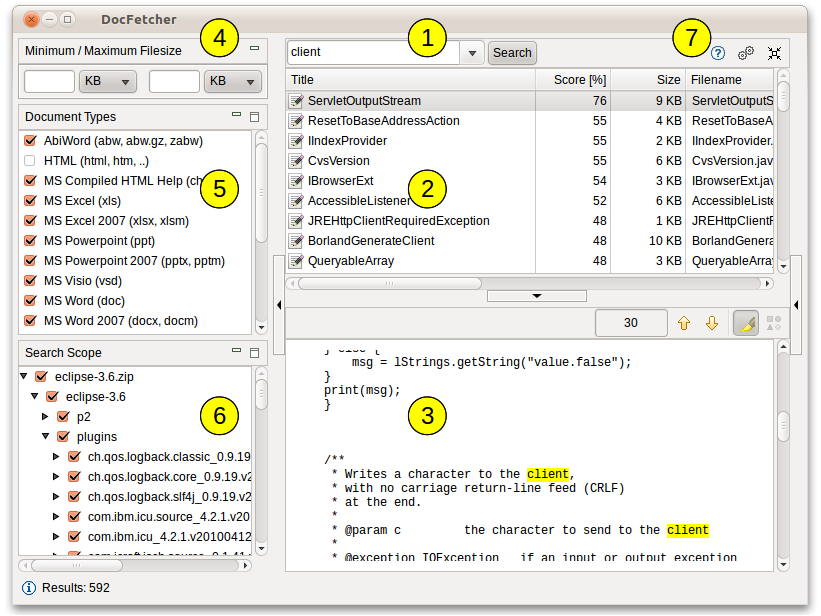
Poniższy zrzut ekranu pokazuje główny interfejs użytkownika. Zapytania są wpisane w polu tekstowym (1) – jeśli chcemy wyszukać frazę, to między wyrazami wstawiamy znak „+” bez spacji. Wyniki wyszukiwania są wyświetlane w okienku wyników (2). Okienko podglądu (3) pokazuje podgląd tylko tekstu pliku aktualnie wybranego w panelu wyników. Wszystkie wyniki poszukiwań są podświetlone na żółto.
Można filtrować wyniki według minimalnego i/lub maksymalnego rozmiaru pliku (4), typu pliku (5) i lokalizacji (6). Przyciski (7) służą do otwierania pomocy, otwierania preferencji i minimalizacji programu do zasobnika.
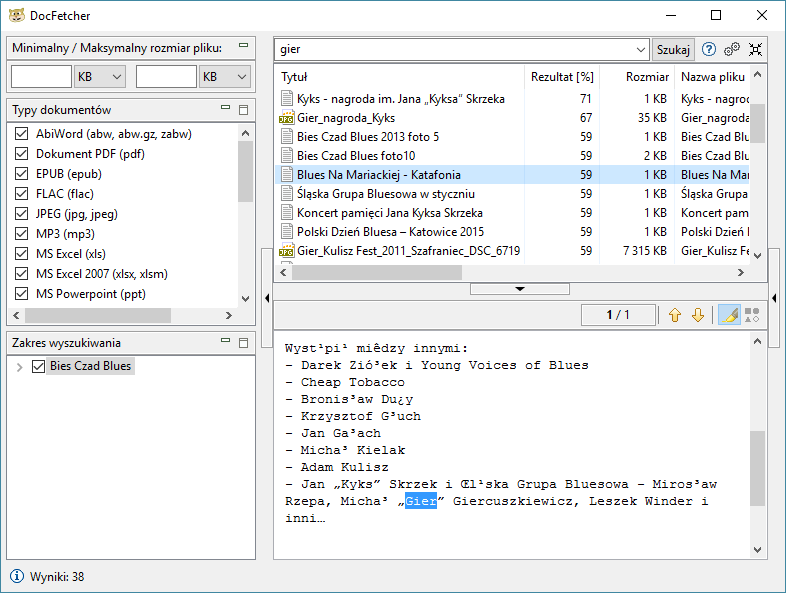
DocFetcher wymaga utworzenia tzw. indeksów dla folderów, które chcemy przeszukać. Indeksowanie pozwala, aby dowiedzieć się bardzo szybko, które pliki zawierają konkretny zestawy słów, co znacznie przyspiesza wyszukiwanie. Aby otworzyć okno „Kolejka indeksowania” klikamy prawym przyciskiem myszy na okno „Zakres wyszukiwania” i wybieramy jakiś folder (lub archiwum) i klikamy „Uruchom”. Proces indeksowania może trochę potrwać, w zależności od liczby i wielkości plików, które mają być indeksowane. Czynność tę robimy tylko raz na poszczególnym folderze. Program aktualizuje tego typu indeksy przy następnym uruchomieniu.
Obsługiwane formaty dokumentów przez program:
- Microsoft Office (doc, xls, ppt)
- Microsoft Office 2007 and newer (docx, xlsx, pptx, docm, xlsm, pptm)
- Microsoft Outlook (pst)
- OpenOffice.org (odt, ods, odg, odp, ott, ots, otg, otp)
- Portable Document Format (pdf)
- EPUB (epub)
- HTML (html, xhtml, …)
- TXT and other plain text formats (customizable)
- Rich Text Format (rtf)
- AbiWord (abw, abw.gz, zabw)
- Microsoft Compiled HTML Help (chm)
- MP3 Metadata (mp3)
- FLAC Metadata (flac)
- JPEG Exif Metadata (jpg, jpeg)
- Microsoft Visio (vsd)
- Scalable Vector Graphics (svg).
Zaloguj
lub
Zarejestruj się
aby zobaczyć!
Zaloguj
lub
Zarejestruj się
aby zobaczyć!
Instalator:
Zaloguj
lub
Zarejestruj się
aby zobaczyć!
Portable:
Zaloguj
lub
Zarejestruj się
aby zobaczyć!
Program do poprawnego działania wymaga w systemie środowiskaZaloguj lub Zarejestruj się aby zobaczyć!
Ostatnia edycja: